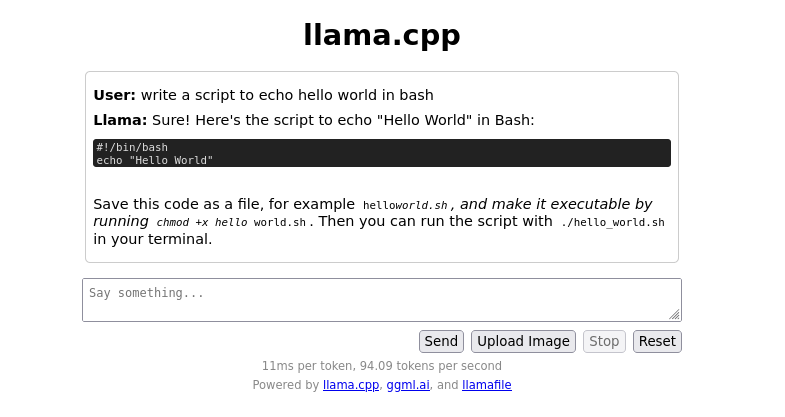
Well, last week I picked up the 3090 GPU. This week I need to try to use it. That is not an easy feat because “drivers.”
My good old workstation is on Ubuntu 20.04. I should probably upgrade. I should probably not use this machine for AI work. But, I am.
Currently I’m using the nvidia-driver-470 that I’ve had for a while, as though it’s some sort of cherished antique that I’ll hand down to my children. I do remember it being a pain to get working, back when I only had one GPU.
$ dpkg --list | grep nvidia-driver
ii nvidia-driver-460 470.223.02-0ubuntu0.20.04.1 amd64 Transitional package for nvidia-driver-470
ii nvidia-driver-470 470.223.02-0ubuntu0.20.04.1 amd64 NVIDIA driver metapackage
But to use a llamafile I need the right CUDA toolkit and driver match up. At first I installed 12.3, but then realized that’s not the driver I have. Need to match those up.
$ ./llava-v1.5-7b-q4-server.llamafile --n-gpu-layers 35
building ggml-cuda with nvcc -arch=native...
nvcc fatal : Unsupported gpu architecture 'compute_30'
/usr/local/cuda-12.3/bin/nvcc: returned nonzero exit status
building nvidia compute capability detector...
cudaGetDeviceCount() failed: CUDA driver version is insufficient for CUDA runtime version
error: compute capability detector returned nonzero exit status
Driver:
$ nvidia-smi | grep CUDA
| NVIDIA-SMI 470.223.02 Driver Version: 470.223.02 CUDA Version: 11.4 |
I didn’t want to break my workstation and thus for now wanted to stay on the 470 driver. So I installed the 11.4 CUDA toolkit.
First I purged the 12.3 CUDA toolkit:
$ dpkg -l | grep -E "cuda|cublas|cufft|cufile|curand|cusolver|cusparse|gds-tools|npp|nvjpeg|nsight|nvvm"
$ # review that list
$ # now remove
sudo apt-get --purge remove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" \
"*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*" "*nvvm*"’’’
NOTE: This requires setting up the NVIDIA repo! Not shown here.
Then I installed the 11.4 CUDA toolkit:
$ sudo apt-get install cuda-toolkit-11-4
Added this to my path:
$ which nvcc
/usr/local/cuda-11.4/bin/nvcc
Next I tried to run the llamafile again:
$ ./llava-v1.5-7b-q4-server.llamafile --n-gpu-layers 35
building ggml-cuda with nvcc -arch=native...
nvcc fatal : Value 'native' is not defined for option 'gpu-architecture'
/usr/local/cuda-11.4/bin/nvcc: returned nonzero exit status
building nvidia compute capability detector...
building ggml-cuda with nvcc -arch=compute_86...
NVIDIA cuBLAS GPU support successfully loaded
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6
Device 1: NVIDIA GeForce GTX 660 Ti, compute capability 3.0
cuBLAS error 3 at /home/curtis/.llamafile/ggml-cuda.cu:6091
current device: 1
But it was using the wrong card. I believe the error was due to using the old 660Ti and trying to compile for it using CUDA 11.4.
Setting CUDA_VISIBLE_DEVICES=0 fixed that:
$ env | grep CUDA
CUDA_VISIBLE_DEVICES=0
$ ./llava-v1.5-7b-q4-server.llamafile --n-gpu-layers 35
NVIDIA cuBLAS GPU support successfully loaded
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6
{"timestamp":1702258585,"level":"INFO","function":"main","line":2650,"message":"build info","build":1500,"commit":"a30b324"}
{"timestamp":1702258585,"level":"INFO","function":"main","line":2653,"message":"system info","n_threads":6,"n_threads_batch":-1,"total_threads":12,"system_info":"AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | "}
Multi Modal Mode Enabledclip_model_load: model name: openai/clip-vit-large-patch14-336
clip_model_load: description: image encoder for LLaVA
clip_model_load: GGUF version: 3
clip_model_load: alignment: 32
clip_model_load: n_tensors: 377
clip_model_load: n_kv: 19
clip_model_load: ftype: q4_0
SNIP!
That’s about as far as I’m getting this weekend.
Here’s a fun command to watch the GPU:
nvidia-smi --query-gpu=timestamp,name,pci.bus_id,driver_version,pstate,pcie.link.gen.max,pcie.link.gen.current,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv -l 5